Zhen Zhu
Envision the whole of you.
CS Ph.D. candidate at University of Illinois at Urbana-Champaign (UIUC).

Welcome! I’m currently a final year Ph.D. candidate at the University of Illinois at Urbana-Champaign (UIUC), working with Professor Derek Hoiem. I received my Master’s degree from HUST in June 2020, supervised by Professor Xiang Bai.
My research goal is to close the loop between perception and creation by building on device multimodal models that learn a concept from few interactions and quickly reuse that knowledge to recognize, reason, and reshape the visual world.
Research Focus
- Continual & Dynamic Learning — algorithms that update models in real time without forgetting.
- Multimodal Models — factual and grounded large multimodal models that integrate images, text, video, etc.
- Controllable Synthesis — autoregressive/diffusion-based models for fast, precise and user-directed editing.
- Visual Recognition — models for fundamental visual understanding, such as object detection and segmentation.
I am currently on the job market for tenure-track faculty, postdoctoral, and research scientist positions beginning in around early 2026. Feel free to reach out if our interests align.
More about me: CV · Google Scholar
2018
-
Abstract: Object detection is an important and challenging problem in computer vision. Although the past decade has witnessed major advances in object detection in natural scenes, such successes have been slow to aerial imagery, not only because of the huge variation in the scale, orientation and shape of the... Read more
-

Abstract: The real world exhibits an abundance of non-stationary textures. Examples include textures with large-scale structures, as well as spatially variant and inhomogeneous textures. While existing example-based texture synthesis methods can cope well with stationary textures, non-stationary textures stil... Read more
-
Abstract: Text in natural images is of arbitrary orientations, requiring detection in terms of oriented bounding boxes. Normally, a multi-oriented text detector often involves two key tasks: 1) text presence detection, which is a classification problem disregarding text orientation; 2) oriented bounding box r... Read more

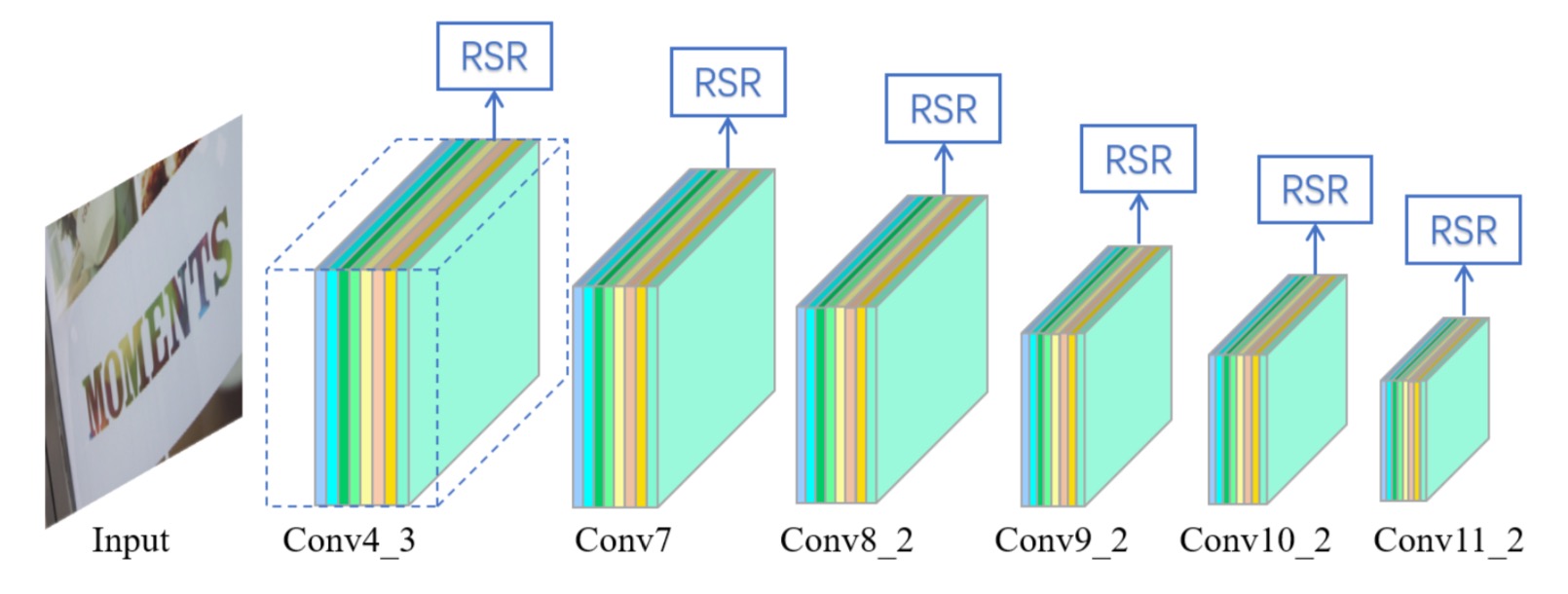
2019
-
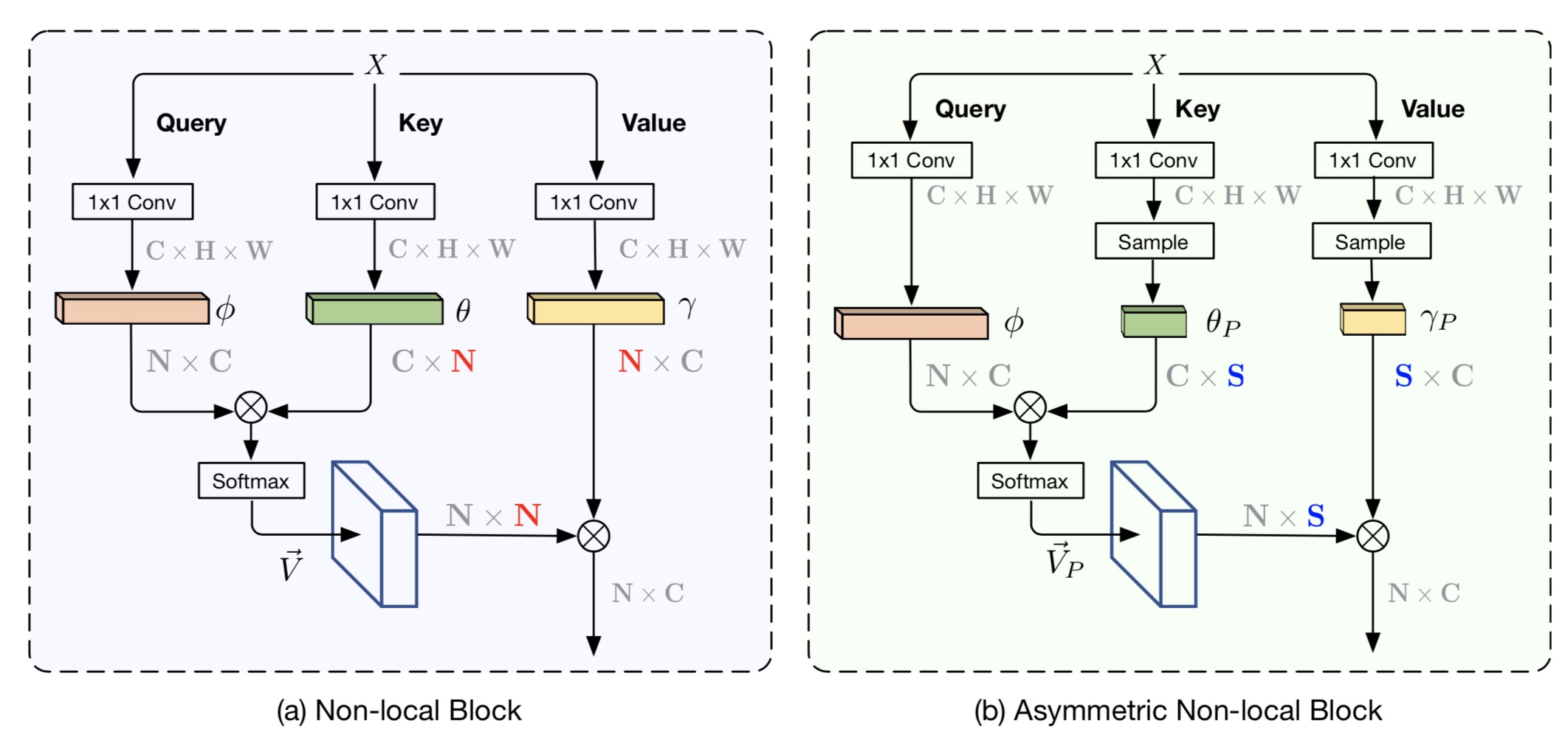
Abstract: The non-local module works as a particularly useful technique for semantic segmentation while criticized for its prohibitive computation and GPU memory occupation. In this paper, we present Asymmetric Non-local Neural Network to semantic segmentation, which has two prominent components: Asymmetric P... Read more
-
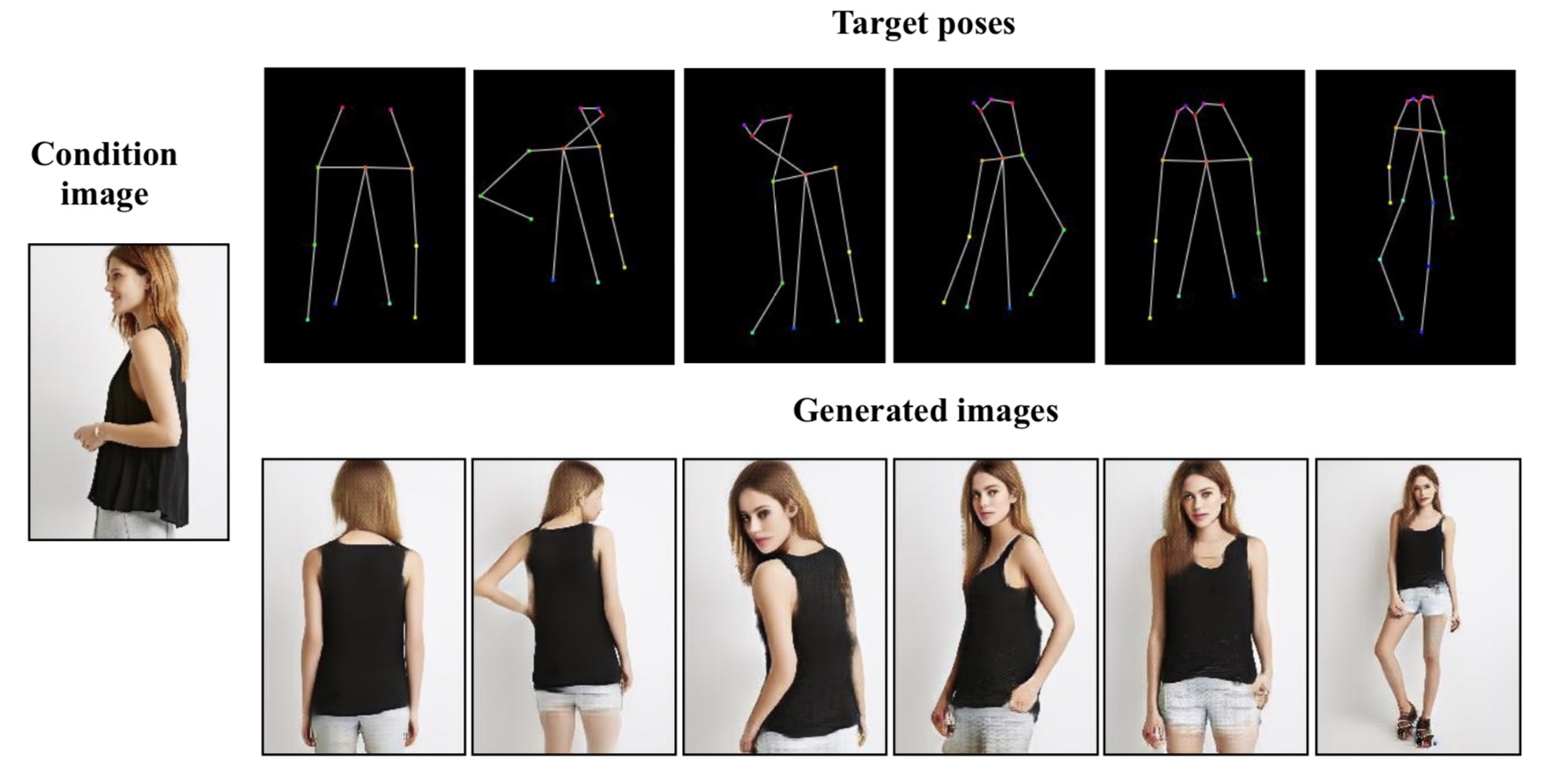
Abstract: This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. The generator of the network comprises a sequence of Pose-Attentional Transfer Blocks that each transfers certain regions it attends to, generating the person i... Read more
2020
-
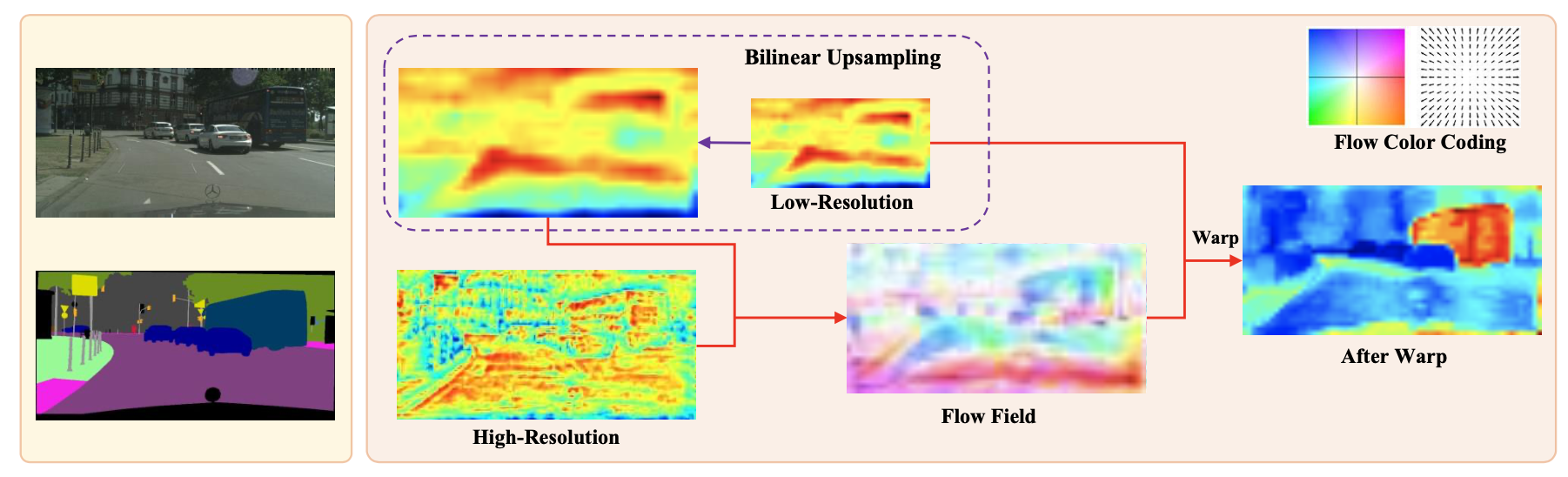
Abstract: In this paper, we focus on designing effective method for fast and accurate scene parsing. A common practice to improve the performance is to attain high resolution feature maps with strong semantic representation. Two strategies are widely used – atrous convolutions and feature pyramid fusion, are ... Read more
-
Abstract: In this paper, we focus on semantically multi-modal image synthesis (SMIS) task, namely, generating multi-modal images at the semantic level. Previous work seeks to use multiple class-specific generators, constraining its usage in datasets with a small number of classes. We instead propose a novel G... Read more

2021
-
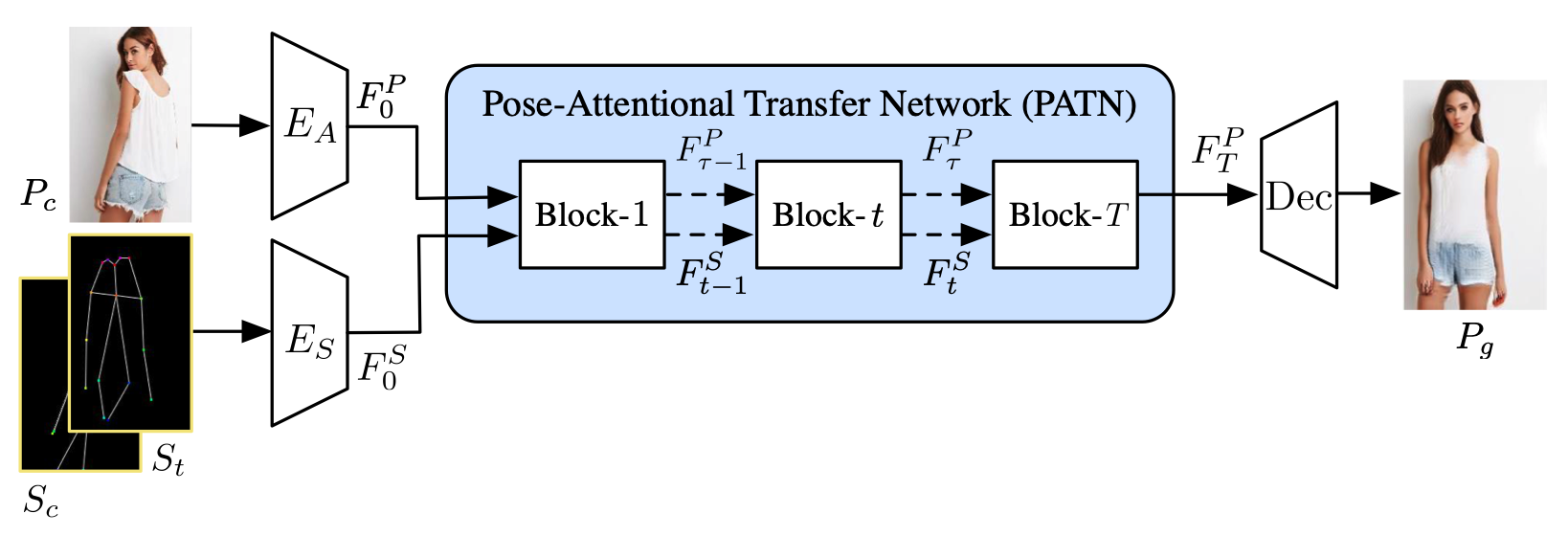
Abstract: This paper proposes a new generative adversarial network for pose transfer, i.e., transferring the pose of a given person to a target pose. We design a progressive generator which comprises a sequence of transfer blocks. Each block performs an intermediate transfer step by modeling the relationship ... Read more
2022
-
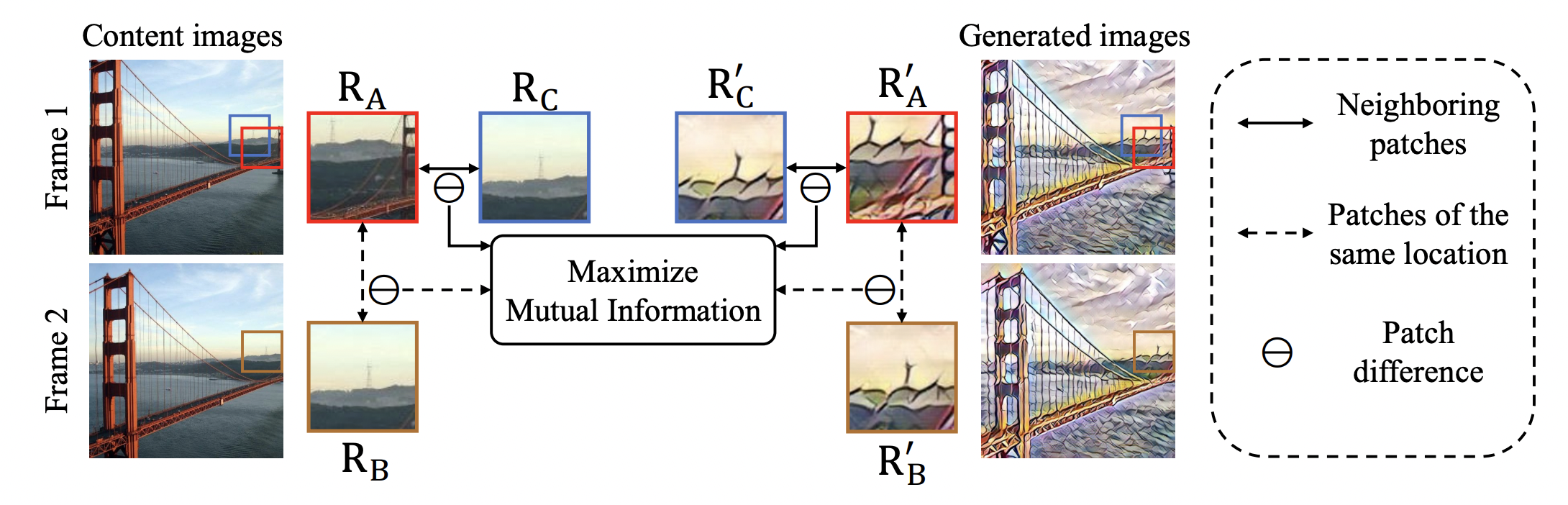
Abstract: In this paper, we aim to devise a universally versatile style transfer method capable of performing artistic, photo-realistic, and video style transfer jointly, without seeing videos during training. Previous single-frame methods assume a strong constraint on the whole image to maintain temporal con... Read more
2024
-

Abstract: We propose an approach for anytime continual learning (AnytimeCL) for open vocabulary image classification. The AnytimeCL problem aims to break away from batch training and rigid models by requiring that a system can predict any set of labels at any time and efficiently update and improve when recei... Read more
-
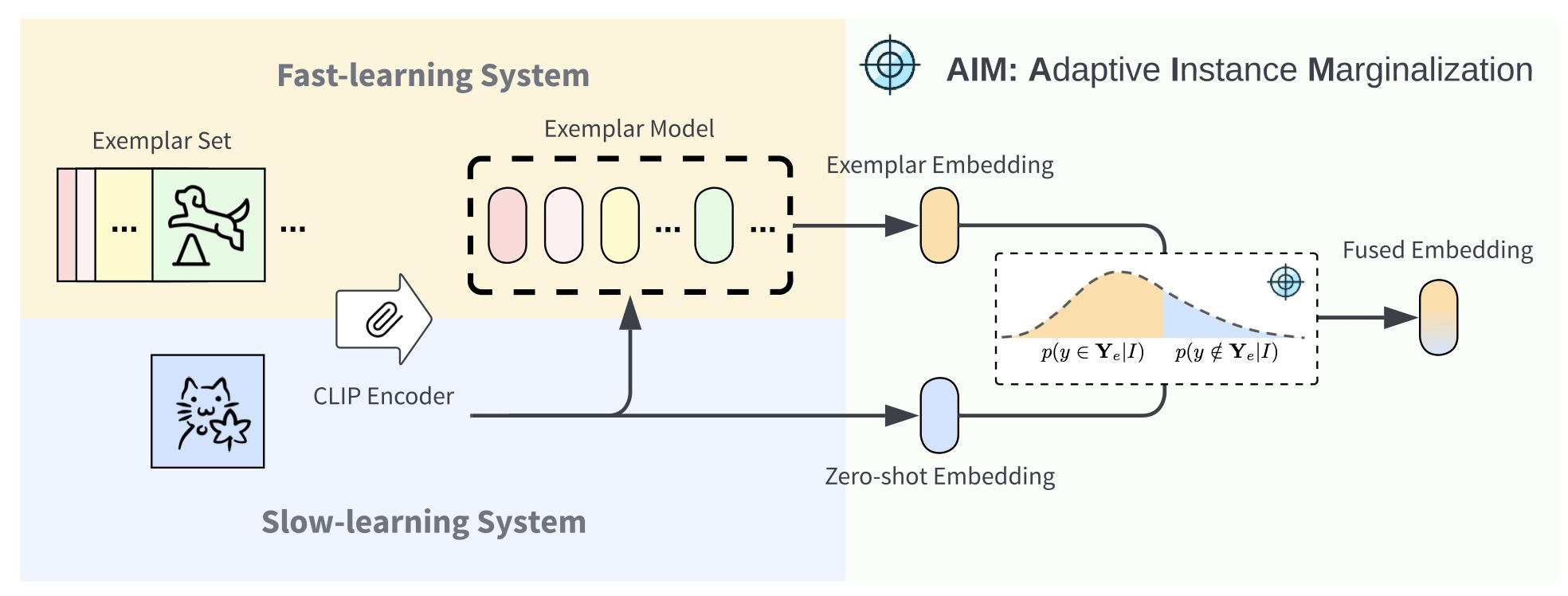
Abstract: We introduce a method for flexible and efficient continual learning in open-vocabulary image classification, drawing inspiration from the complementary learning systems observed in human cognition. Specifically, we propose to combine predictions from a CLIP zero-shot model and the exemplar-based mod... Read more
2025
-
Abstract: Large multimodal models (LMMs) are effective for many vision and language problems but may underperform in specialized domains such as object counting and clock reading. Fine-tuning improves target task performance but sacrifices generality, while retraining with an expanded dataset is expensive. We... Read more
- 2025 Under ReviewUnder Review
Abstract: Image-text models excel at image-level tasks but struggle with detailed visual understanding. While these models provide strong visual-language alignment, segmentation models like SAM2 offer precise spatial boundaries for objects. To this end, we propose TextRegion, a simple, effective and training-... Read more
Collaborations
I've had the privilege of mentoring several talented students throughout my Ph.D. journey:
- Zhiliang Xu — Image Generation and Face Synthesis
- Yang Liu — Watermark Removal and Image Processing
- Zijie Wu — Style Transfer and Generative Models
- Yiming Gong — Machine Learning and Image Editing
- Joshua Cho — Computational Photography and Image Enhancement
- Xudong Xie — Texture Synthesis
My current close collaborators:
- Yao Xiao — Video Understanding and Multimodal Learning
- Zhipeng Bao — Multimodal Generation
Service
Co-organizer: UIUC External Speaker Series — Interested speakers are welcome to reach out to register for upcoming sessions
Co-organizer: UIUC Vision Mini-Conference
Conference Reviewer: CVPR, ICCV, ECCV, ICLR, NeurIPS, ICML, AAAI, IJCAI, BMVC, WACV, and others
Journal Reviewer: TPAMI, IJCV, TIP, PR, and others